The Raster Graphics Pipeline

Figure 0
: Composite output from the provided sample rasterizer code[1].This tutorial is intended to be a crash course in raster graphics theory. It should give you enough context to know what the operations you're doing mean when using a graphics API like OpenGL or Direct3D (we won't focus on either API's details, but everything is described OpenGL-centric). This tutorial is intended to be a complete, yet concise, explanation of the graphics pipeline. Jargon to know is highlighted
Since code is worth a thousand words, I have written a sample 3D CPU-based rasterizer that demonstrates the basics (see Figure 0). It doesn't do all operations in a full graphics pipeline, but it does most of the key steps in a conceptually correct way, and importantly it does them simply, so you can follow and learn from it. This tutorial does not refer to that code specifically, but it may be helpful for reference as you read.
Contextual Survey

Figure 1
: NVIDIA GPU, apparently a GTX 275 (very dated now, but pretty).The
Figure 2
: Logos for the OpenGL and Vulkan graphics APIs (images' source).There are also
The rest of this tutorial presents an idealized version of the
- Application Stage: the programmer (you!) talks to the graphics API, controlling the following steps and providing data to draw.
- Geometric Stage(s): transformation of the geometric data to pixel coordinates.
- Rasterization Stage: conversion of geometry from vectors into pixels.
- Fragment Stage: assigning color/depth to each pixel.
- Framebuffer Stage: test the incoming pixel to see if it should be visible.
- Screen Stage: the memory on the GPU is displayed onto the screen.
Application Stage
This is where your program runs, handling everything your GPU doesn't (like your application's logic, AI, maybe some physics, etc.). Graphics-wise, you talk to the GPU through a series of API commands (
The first thing you have to do is set up a
You must also specify your geometric data to the GPU so that it has something to actually draw. Essentially, you upload buffer(s) of data called a
You must also set up the GPU's internal state to configure how it renders, for example with calls like (OpenGL) glEnable(⋯). Nowadays[5], you must also provide details for how (minimally) the vertex stage works, in the form of a
Finally, you tell the graphics API to draw using the GPU's current state (e.g. with OpenGL) glDrawArrays(⋯) (VBOs) or glDrawElements(⋯) (VBOs and IBO). These calls essentially tell the GPU to start rendering a bunch of
Geometric Stage(s)
The GPU has been told to draw something, and it has a bunch of geometric vertex data that's supposed to be connected up somehow. The geometry you provide is specified in some
The job of the geometric stage(s) is fundamentally to convert from object-space to screen-space. The quintessential, required, geometric stage is the
There are actually a bunch of different spaces we should consider. Most transformations between spaces are done by a
Object-, World-, and Eye-Space
First, there's the aforementioned
Next, there's the
Next comes
Clip-Space, NDC, and Perspective
Next, we distort eye-space according to e.g. 3D perspective. There are three key stages to this: (1) the

Figure 3
: The viewing frustum implied by a 3D perspective projection matrix (image source).Imagine a 3D pyramid with the top cut off (see Figure 3), a shape called a
The overall perspective transform distorts this frustum into a rectangular solid, which accomplishes the effect of perspective (note: for 2D rendering, the frustum is actually a rectangular solid to start with, so the transform just rescales it).
After we multiply an eye-space vertex (which is of the form \(\langle x,y,z,1 \rangle\)) by the \(4\times 4\) projection matrix, we'll get a new \(4\times 1\) vertex in clip-space. However, the final component (the \(w\)-component) will no longer be \(1\). This is because the clip-space vertex is in
The final step will be to recover the 3D world by dividing by the \(w\)-component, something like \(\langle ~x/w,~y/w,~z/w,~w/w~ \rangle\), the
However, we cannot go ahead and divide just yet! One reason why is that a vertex behind the camera will turn out to have a negative \(w\)-component. When we divide by \(w\), the sign of the \(\langle x,y,z\rangle\) coordinates will flip, effectively putting that vertex in front of the camera! Another reason is that vertices that are outside the frustum shouldn't be drawn, because they wouldn't show up on the screen, and we shouldn't waste time drawing them!
Thus, the GPU first performs
At this point, the GPU can then safely and logically divide all vertices by their \(w\)-components. Again, this is called the
Note that the \(w\)-component of all vertices will now naturally be \(1\) (because \(w/w=1\)). We can thus throw away the fourth component, returning back to our 3D universe. However, in the rasterization stage, it will turn out we'll need \(1/w\) from each vertex, so we do still need to save that somewhere[10].
Viewport
From here, we apply the
Programming and Stages
Everything up through multiplication by the projection matrix, you need to specify in a shader[11]. The clipping, perspective divide, and viewport transform are (thankfully) done for you, though it's still useful to know about them.
At minimum, you must define a
There are, however, additional, optional stages you can tack on after the vertex stage. You can enable
Rasterization Stage
At this point, the base primitives are now defined in terms of coordinates on the screen. The \(x\)- and \(y\)-components define the \(x\)- and \(y\)-position of the vertices on the screen, while the \(z\)-component is related to the
The general (and in some implementations, only) case is that the base primitive is a triangle, so we'll assume that that's what we're working with in the following.

Figure 4
: (image source).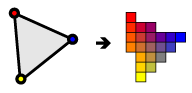{kind=link}
Triangles to Fragments
A triangle is still defined by its vertices, three infinitely small mathematical points, but we want to have pixels! In this stage, the rasterizer does the first step of that, converting the three points into a set of
The rasterizer finds the set of pixels the triangle covers, and creates a fragment at each such pixel's location[12]. This is accomplished by sophisticated 'edge-walking' algorithms that minimize wasted computational effort. Many rasterization algorithms also try to output fragments that are physically close together at the same time to maximize
After rasterization, the fragments go on to the fragment stage, where their final attribute(s) are computed.
Interpolating Attributes
The vertex attribute(s) stored for each vertex must be interpolated to each fragment. For example, the vertices could have texture coordinate and normal attributes, which need to be interpolated onto the intermediate locations of the pixels subtended by the triangle. Also, so that non-orthogonal triangles display correctly, we must do this with
Doing this is a little tricky, and it's easiest to express with actual math. Let's say we have a screen-space triangle with vertex positions \(\vec{p}_a\), \(\vec{p}_b\), and \(\vec{p}_c\). Every point in the triangle can be expressed as a linear combination of these positions:
\[ \vec{p}(\alpha,\beta,\gamma) = \alpha \,\vec{p}_a + \beta \,\vec{p}_b + \gamma \,\vec{p}_c \]The weights \(\langle\alpha,\beta,\gamma\rangle\) are called
Remember how we divided by the clip-space \(w\)-component, but I said we needed to keep it around? This is why. Ordinary attributes \(\vec{h}\), such as the texcoord or normal, get interpolated using the following formula:
\[ \vec{h} = \frac{ \alpha \,\vec{h}_a / w_{a,\text{clip}} + \beta \,\vec{h}_b / w_{b,\text{clip}} + \gamma \,\vec{h}_c / w_{c,\text{clip}} }{ \alpha / w_{a,\text{clip}} + \beta / w_{b,\text{clip}} + \gamma / w_{c,\text{clip}} } \]That is, we interpolate \(\vec{h}/w_\text{clip}\) and \(1/w_\text{clip}\) from each vertex to the fragment location, then divide the former by the latter to get the value at the fragment. This results in perspective-correct interpolation[14]. We can factor out the common factors to make it more efficient:
\[ \vec{h} = \left( \frac{1}{ \alpha / w_{a,\text{clip}} + \beta / w_{b,\text{clip}} + \gamma / w_{c,\text{clip}} } \begin{bmatrix} \alpha / w_{a,\text{clip}} \\ \beta / w_{b,\text{clip}} \\ \gamma / w_{c,\text{clip}} \end{bmatrix} \right) \dotprod \begin{bmatrix} \vec{h}_a \\ \vec{h}_b \\ \vec{h}_c \end{bmatrix} \]This is better because the parenthesized vector can be reused for any number of vertex attributes. You can think of this as calculating perspective-corrected barycentric coordinates, and then doing the interpolation in eye-space.
Understanding Depth
Depth needs to be interpolated too, but the method is different[14]. Before we do that, we need to first take a step back and understand what's going on. The viewport transform from NDC to screen-space for depth is just:
\[ z_\text{screen} = \frac{1}{2} z_\text{ndc} + \frac{1}{2} \]This just remaps NDC \([-1,+1]\) to screen-space \([0,1]\). In turn, NDC is calculated from clip-space by the perspective divide, as we saw in the previous section:
\[ z_\text{ndc} = \frac{z_\text{clip}}{w_\text{clip}} \]In turn, clip-space \(z_\text{clip}\) and \(w_\text{clip}\) are calculated from the eye-space \(z_\text{eye}\) and \(w_\text{eye}\) (\(=1\)) in the following way (this follows immediately from multiplying an eye-space vertex by the definition of the projection matrix). Here, \(n\) and \(f\) are the near and far clipping planes, and we're assuming a perspective projection:
\begin{align*} z_\text{clip} &= \frac{f+n}{f-n} z_\text{eye} - \frac{2 f n}{f - n} \\ w_\text{clip} &= -z_\text{eye} \end{align*}
Figure 5
: Screen-space depth (\(z_\text{screen}\)) vs. eye-space \(z\)-component (\(z_\text{eye}\)). Distance ahead of the camera increases from right to left. Notice the nonlinear distortion; depth is not a spatial coordinate!Thus, putting it all together, the screen-space depth can be related to eye-space depth as (again, for a perspective projection):
\begin{align*} z_\text{screen} &= \frac{1}{2}\left(\frac{2 n f}{f-n} \cdot \frac{1}{z_\text{eye}} + \frac{f+n}{f-n}\right) + \frac{1}{2} \\ &= \frac{f}{f-n} \left( \frac{n}{z_\text{eye}} + 1 \right) \end{align*}You can check this—if you put in \(z_\text{eye}=-n\) (remember that in eye-space we're looking down the negative \(z\)-axis, so negative numbers are in front of the camera), then you can calculate that you get out \(z_\text{screen}=0\) for screen-space, the nearest value. Similarly, if you put in \(z_\text{eye}=-f\), you get out \(z_\text{screen}=1\), the farthest. See Figure 5.
Pay attention to the form of the equation, though. The screen-space depth \(z_\text{screen}\) is inversely related to the eye-space depth \(z_\text{eye}\)! This is very counterintuitive. However, there is a good reason for it: the precision of the depth buffer gets 'concentrated' nearer to the eye. This is useful because closer objects get more detail[15].
Interpolating Depth
Another reason is that interpolating depth is very simple. Although eye-space depth is not linear in screen-space, the reciprocal of depth is, and so interpolating the depth (again, vertices \(a\), \(b\), and \(c\), with corresponding barycentric coordinates \(\langle\alpha,\beta,\gamma\rangle\)) is as simple as:
\[ z_\text{screen} = \alpha \,z_{a,\text{screen}} + \beta \,z_{b,\text{screen}} + \gamma \,z_{c,\text{screen}}\hspace{1cm}\text{(correct interpolation)} \]This usually causes some confusion, which should hopefully already be somewhat alleviated by the above, but let's address it explicitly. It is quite common[16] to say that to get depth \(z^*\), you should interpolate \(1/z\) and then take the reciprocal (where it's not clear what space \(z\) and \(z^*\) are in):
\[ z^* = \frac{1}{\text{interpolate}( 1 / z )}\hspace{1cm}\text{(common)} \]This is somewhere between a simplification and a misunderstanding. With a simpler projection matrix, we might have that \(z_\text{screen}=1/z_\text{eye}\) exactly. This is actually part of the legitimate derivation of the interpolation for depth[14]. Then, if we take the reciprocal of this, we get depth in screen-space. That is, depth is the reciprocal of the interpolated reciprocal \(z_\text{eye}\). However, screen-space depth \(z_\text{screen}\) is not defined to be physical depth; it is actually inversely related (on purpose, for better precision), and it's also not an exact reciprocal relationship. So we could say:
\[ \text{depth} \approx \frac{1}{z_\text{screen}} \approx \frac{1}{\text{interpolate}( 1 / z_\text{eye} )}\hspace{1cm}\text{(sortof)} \]
Figure 6
: Lighting components (top to bottom: ambient, diffuse, specular, combined) used in a basic lighting model. Better lighting models exist, but this one is simple and time-honored. (Adapted from image source.){kind=link}
Fragment Stage
Here, the fragments are prepared for entry into the framebuffer. This basically involves computing the final values for the fragment's attributes.
The most obvious fragment stage operation is to determine a color for the fragment. Normally, the fragment shader you provided in the application stage runs here, once for each fragment[17]. Computing the color usually involves running a local lighting model (i.e., a virtual material, defined through textures, lit by one or more virtual lights).
The output of this stage is a fragment with more limited information—intuitively, just a color, depth, and location. You can have multiple colors, alter the depth, and mess with the stencil buffer or GPU memory, but most of the time your fragment shader only cares about computing one color (given the complexity of some material models, that can be quite difficult enough!).
A basic and common model, popular since the early days of computer graphics[18], is to break the lighting model into three terms:
To understand ambient, imagine standing in a dark room, shining a flashlight at the floor. If you look up, you will still see the ceiling, even though no light from the flashlight is directly hitting it. This
To understand diffuse, imagine shining your flashlight at a sphere. The place on the sphere that's facing the flashlight will be brightest. The places farther away are tilted away from the light, meaning the light is more spread out in those areas, and so darker[19]. This is called the diffuse term, and the simplest model is Lambertian which you compute as the dot-product of the normal and light direction.
To understand specular, imagine shining your flashlight at a plastic sphere. You'll notice a bright spot of light on the surface of the sphere. If you keep the flashlight and sphere in one place, but move your head around, you'll see that the location of the spot changes. This spot is at the location where light from the flashlight bounces directly, or nearly directly, off the surface and into your eye. Intuitively, you're looking at an imperfect reflection of the light in the sphere. The spot is called a
Framebuffer Stage
The new fragment must now determine whether (and if so, how) its information should be combined with the data at the corresponding pixel in the framebuffer.
This is accomplished by a series of tests the fragment may have to pass. Most tests are based on comparing the fragment's information to the corresponding values stored in the framebuffer. I'll describe how these tests usually work, though it's worth noting they can be configured to act differently. If a fragment passes all tests, its data is written into the framebuffer. Fragment data can also be combined with the existing data, for example when a color
There are a number of different buffers within the framebuffer. Their names simply refer to the data they store. For example, the
First comes the
Next comes the less common
Next comes the less common
In OpenGL 3.0 and below, next came a test called the
Next comes the extremely important and common
Although these tests all semantically run after the fragment shader executes, some of them can be run before, because the fragment shader does not alter them. These
The pixel ownership test always runs before. The stencil test can run before if the shader is known not to change the stencil value. Same with the depth test for the depth value. If the alpha test exists and is enabled, it could force subsequent early fragment tests to be disabled, because that really does depend on the fragment shader having been executed.
Screen Stage
This is where we finally get to see what happened. The framebuffer contains color values, and these are drawn to the screen. At its most basic, this is the most straightforward stage, because it just involves scanning out the data from the framebuffer to the display hardware.
The display hardware can refresh at a certain rate, usually around 60 Hz for most monitors. The GPU may render faster or slower than this, and this introduces some issues we need to resolve.
The first is that we can't try to display a framebuffer that the GPU is rendering to. Suppose you're rendering a teapot in a room. First the GPU clears the framebuffer, then draws the polygons of the room, then the polygons of the teapot. However, if we tried to display that while the GPU was working on it, some pixels might be black (because the framebuffer has just been cleared), some pixels might show the room without a teapot, some might show the room or teapot partially drawn, and some might actually be right.
To address this, most renderers set up
Although this is significantly better in that the display only ever reads from a completed frame, the buffer swap can still happen partway through the display scanning out the image, meaning that the display will show part of one frame and part of the next. If the frame has a significant amount of motion, you can get an objectionable effect called screen tearing.
We can solve this by making the buffer swap wait for the display to finish drawing the image; this is called
There are more sophisticated approaches such as triple buffering (the GPU can keep working on new frames) and there are nuances to VSync.
Conclusion
At this point, you should know basically how the basic graphics pipeline produces an image from a bunch of triangles. However, we've glossed over some practical details and talked almost nothing about actually commanding the GPU's hardware graphics pipeline, using a graphics API like OpenGL.
For the 'practice' counterpart to 'theory', I again offer a sample CPU rasterizer. It produces a rasterized image (Figure 0) using just simple C++ code. You can follow the whole pipeline through in the code.
For the graphics API side, which is how you would write a practical renderer today, there are lots of resources and approaches—the best of which is hard work and experimentation. Please go explore the world of OpenGL tutorials available on the internet! I provide a few tutorials myself on the parent Resources Page. And, although it's not a tutorial, my PyGame+PyOpenGL Starter Code will get an OpenGL-powered triangle or two on any python programmer's screen in a jiffy.
I hope you found this useful, and best of luck in your graphics journey!
Notes

{kind=link}