CS 6620.001 "Ray Tracing for Graphics" Fall 2014
Welcome to my ray tracing site for the course CS 6620.001, being taught at the University of Utah in Fall 2014 by Cem Yuksel.
Welcome fellow students! I have lots of experience tracing rays, and with graphics in general, and so I'll be pleased to help by giving constructive tips throughout (and I'll also try very hard to get the correct image, or say why particular images are correct as opposed to others). If you shoot me an email with a link to your project, I'm pretty good at guessing what the issues in raytracers are from looking at wrong images.
Hardware specifications, see bottom of page.
Timing information will look like "(#t #s ##:##:##)" and corresponds to the number of threads used, the number of samples (per pixel, per light, possibly explained in context), and the timing information rounded to the nearest second.
Project 9 - "Depth of Field"
I've had physically accurate depth of field implemented for a long time. In fact, my tracer supports any number of optical elements lined up in front of each other (unfortunately, these elements are not first-class tracing objects, so effects like chromatic aberration from the lens(es) aren't yet possible. It has been on my TODO list for a while to support arbitrary primitives with CSG).
I instead used most of the time getting my sampler working the way I wanted.
Last time, I had some nasty cruft of an implementation of adaptive sampling, which worked, but not well enough to my liking. I reimplemented most of it. Now, it is an adaptive sampler, with adaptive subdivision and n-rooks (Latin hypercube) sampling. Correct reconstruction filtering is, unfortunately, still not implemented—although I did make a sample visualizer to help ensure correctness.
The uniform random generator is pretty bad, but it's what I had been using. Interestingly, I found Halton to actually be worse. This happens because for the low minimum number of samples you shoot initially, the Halton pattern doesn't vary among pixels (at least in my implementation) and is not low-discrepancy enough in general. I choose n-rooks because, like the other two, it is simple to compute and easy to implement—but also, it has excellent randomness. Even with four samples per pixel, I am getting great results.
Parallel to all this, I also profiled my code pretty hard. The bottleneck has been figuring out which surfaces the ray is inside. Since each object has a refractive priority, this really amounts to a priority queue. The class that handles this was fairly simple and inefficient. So, I hacked it apart and rewrote it so that it only allocates dynamically if it must. This cut the bottleneck from something around \(80\%\) of the rendering time to more like \(5\%\). My tracer is much faster now.
This gave me the idea to optimize the memory (de)allocation patterns of the framebuffer. This has been a major problem: for a static allocation, the framebuffer is the number of pixels (~\(10^6\)) times the worst case samples per pixel (\(n \cdot 4^{maxsubdivs}\)). Since each sample requires at minimum a position and a color (which could have more than three channels, of course), this gets in the gigabytes sort of range.
Conversely, using a dynamic allocation requires allocating each sample, each of which has a small dynamic array. This allocation pattern is semi-pathological for memory units, which prefer fewer larger allocations. It's not really a problem on modern operating systems, but for memory checkers and debuggers, it's pretty bad.
A smarter thing to do is to allocate each pixel with placement new, but this really doesn't solve the fundamental problem of needing to allocate a dynamic number of samples.
The first thing I tried was giving each pixel a static array, and then transitioning over to a dynamic array if too many samples were needed. This helps a lot, but it's still pretty crufty. For example, since in adaptive subdivision, you fill each given area with a certain number of samples, you actually know whether an area will need the dynamic store (is the number of samples greater than the preallocation size?), and moreover this is the same for every pixel!
So I rewrote the memory allocator for the framebuffer to be a stack-based thing. It allocates pages of several megabytes at a time, and then parcels out pieces of them in a LIFO manner to new allocation requests. It makes things a whole lot faster, even if it's not completely done yet. Notice that we get free locality, too!
Here are some pictures from various points in the story.
Very first adaptive subdivision image visualization (16t 16s 00:03:54):

Glass bunny (various unknowns) (16t 16s? 00:??:??):

Here are some pictures of airplanes. I don't precisely remember what sampling they used. My notes say \(16\), and I think that means \(16\) Halton samples, with the first one adaptive subdivision, and the second no subdivision. This is before the performance fixes. I'm refining the notation for timing. The first number is now the number of samples and the second is the maximum subdivisions. (16t 16,^3?s 00:14:56), (16t 16,^0?s 00:00:51):


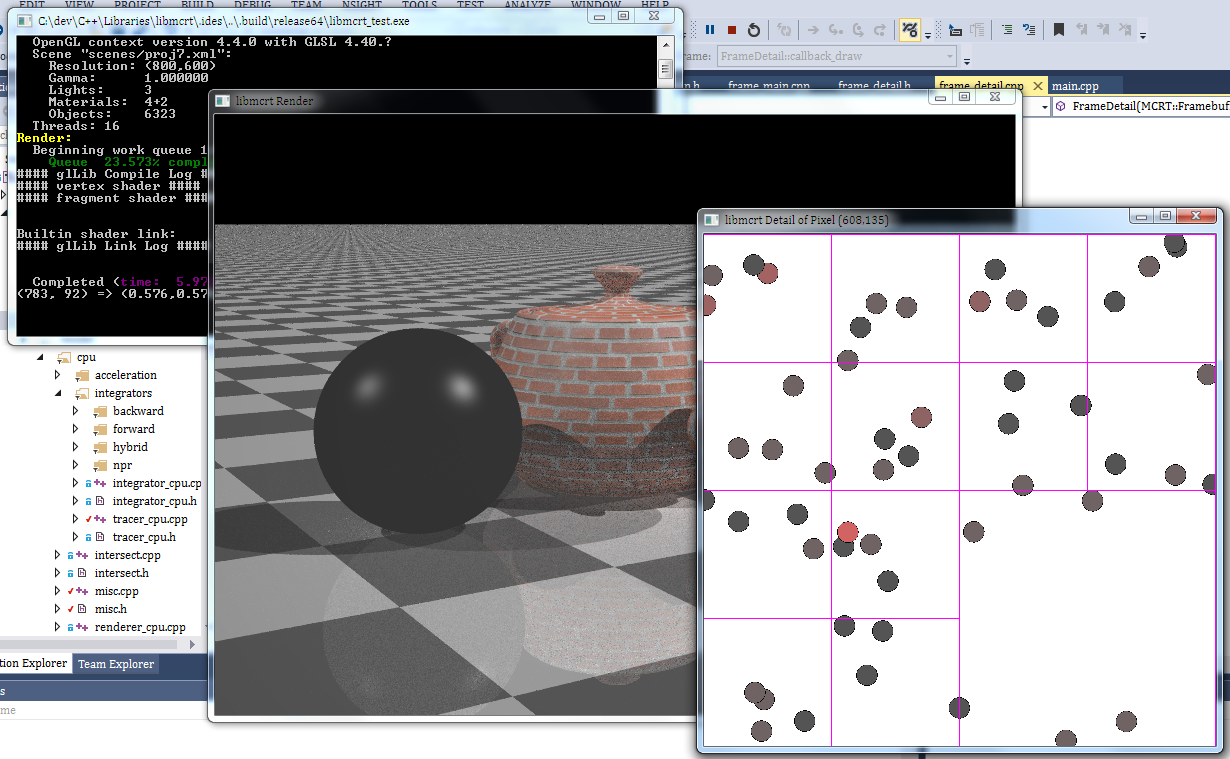
Here's one showing my entire pipeline. The console window in the back gives nice output, including timing projections. The render window shows the progress of an ongoing render. The foreground window shows the location of the samples and the configuration of the subdivisions (here uniform samples). Timing not available:
Here are some more renders, made after fully fixing the memory allocator. Allocation and deallocation time is negligible!
The sampling is still minorly incorrect. I had wanted to fix that and add depth of field, but meetings ran long on Tuesday.
(16t 4,^2s 00:01:07):

(16t 64,^2s 00:05:45):

Proceed to the Previous Project or Next Project.
Hardware
Except as mentioned, renders are done on my laptop, which has:
- Intel i7-990X (12M Cache, [3.4{6|7},3.73 GHz], 6 cores, 12 threads)
- 12 GB RAM (DDR3 1333MHz Triple Channel)
- NVIDIA GeForce GTX 580M
- 750GB HDD (7200RPM, Serial-ATA II 300, 16MB Cache)
- Windows 7 x86-64 Professional (although all code compiles/runs on Linux)